LOWYA(ロウヤ)とは?
「おしゃれな家具は見てるだけでも楽しい!」「家具の基本的なサイズ感は抑えてるので、ネットストアでいろいろ物色したい!」
そんな風に思われている方におすすめのオンラインストアが「LOWYA」です。LOWYAはベッド、デスク、食器棚、ソファなどの大型家具から、バス・トイレ、キッチンに使えるおしゃれなインテリア雑貨、便利な収納ラック・グッズまで幅広く取り揃えられた総合通販サイトです。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
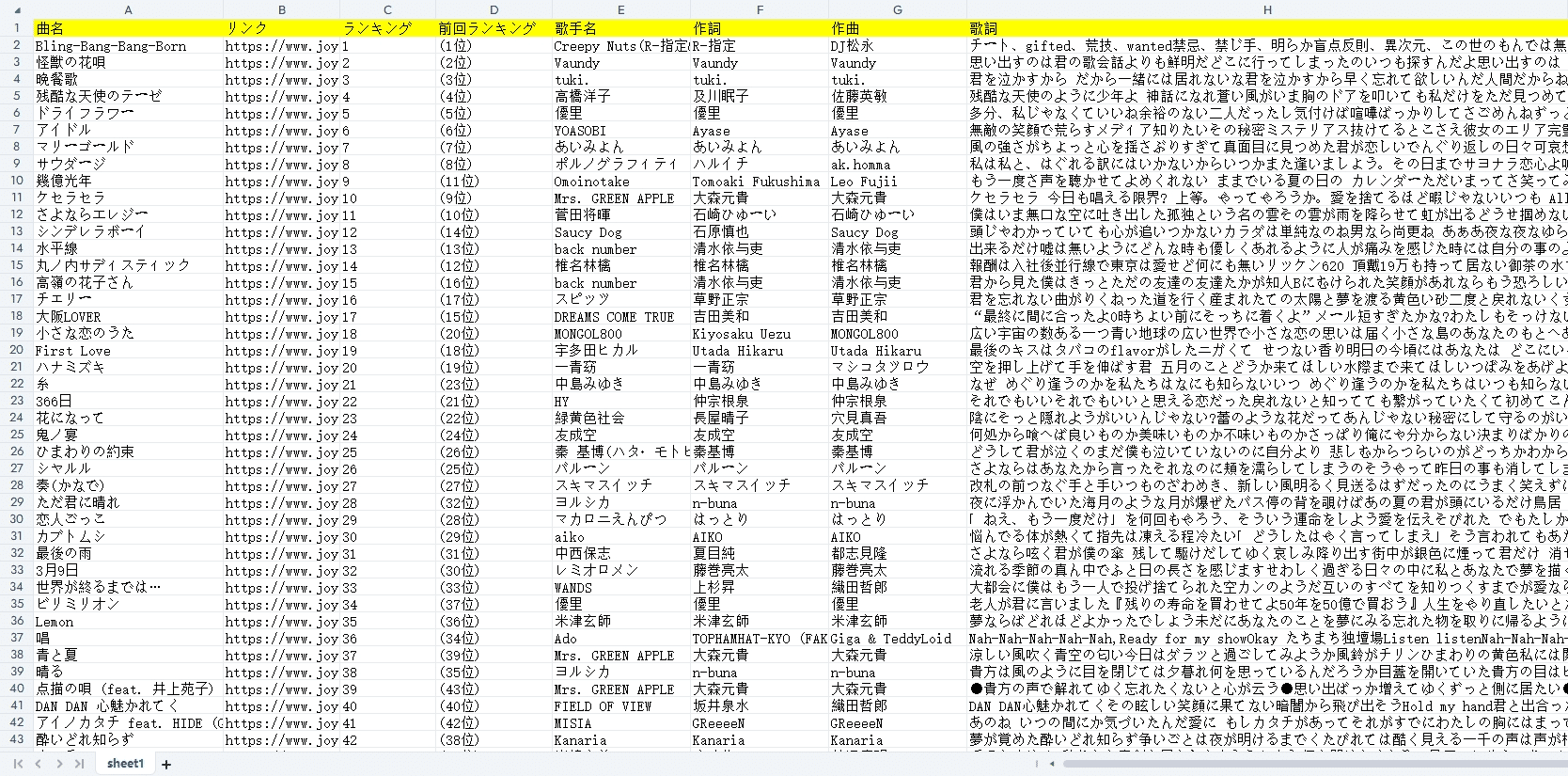
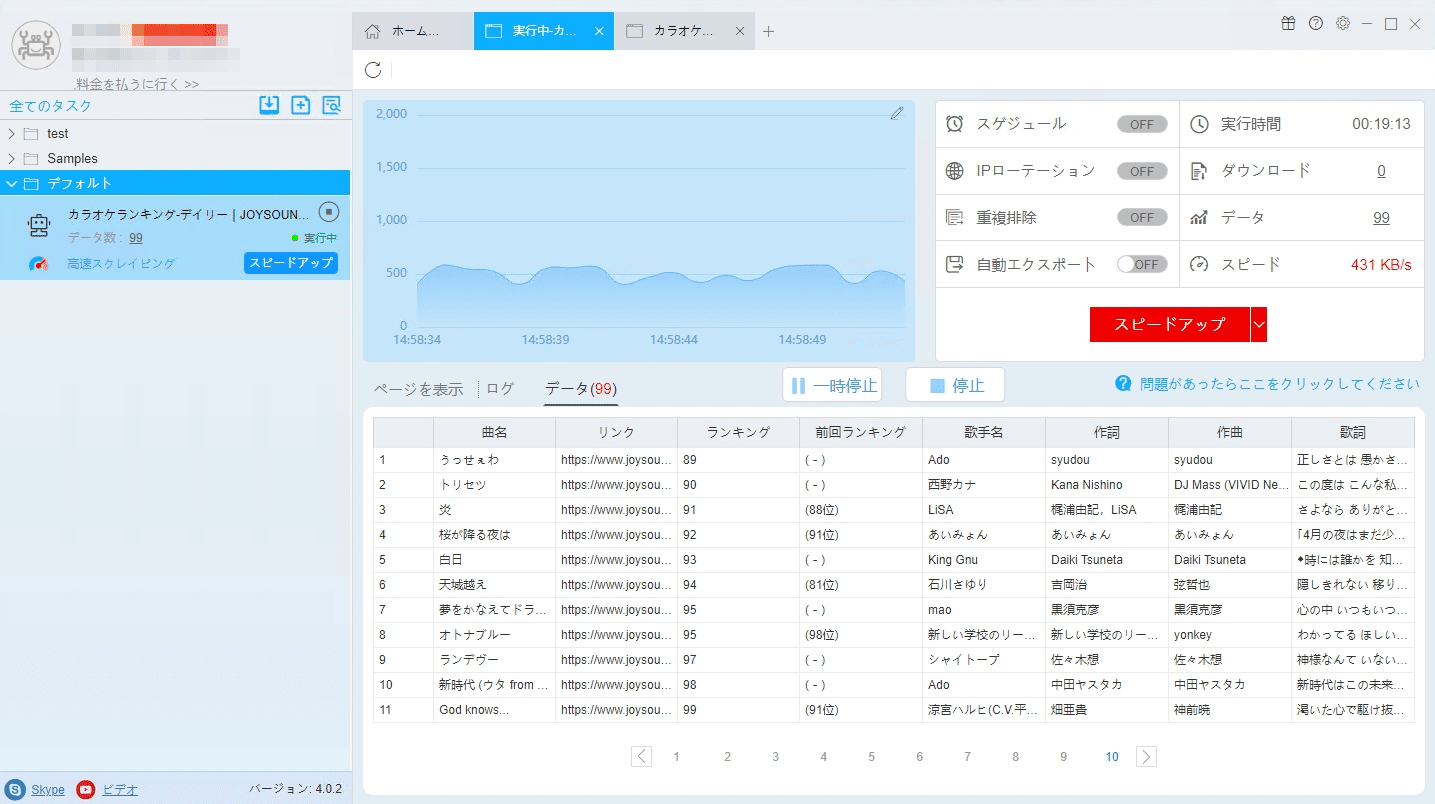
抽出されたデータをご覧ください。

1.タスクを新規作成する
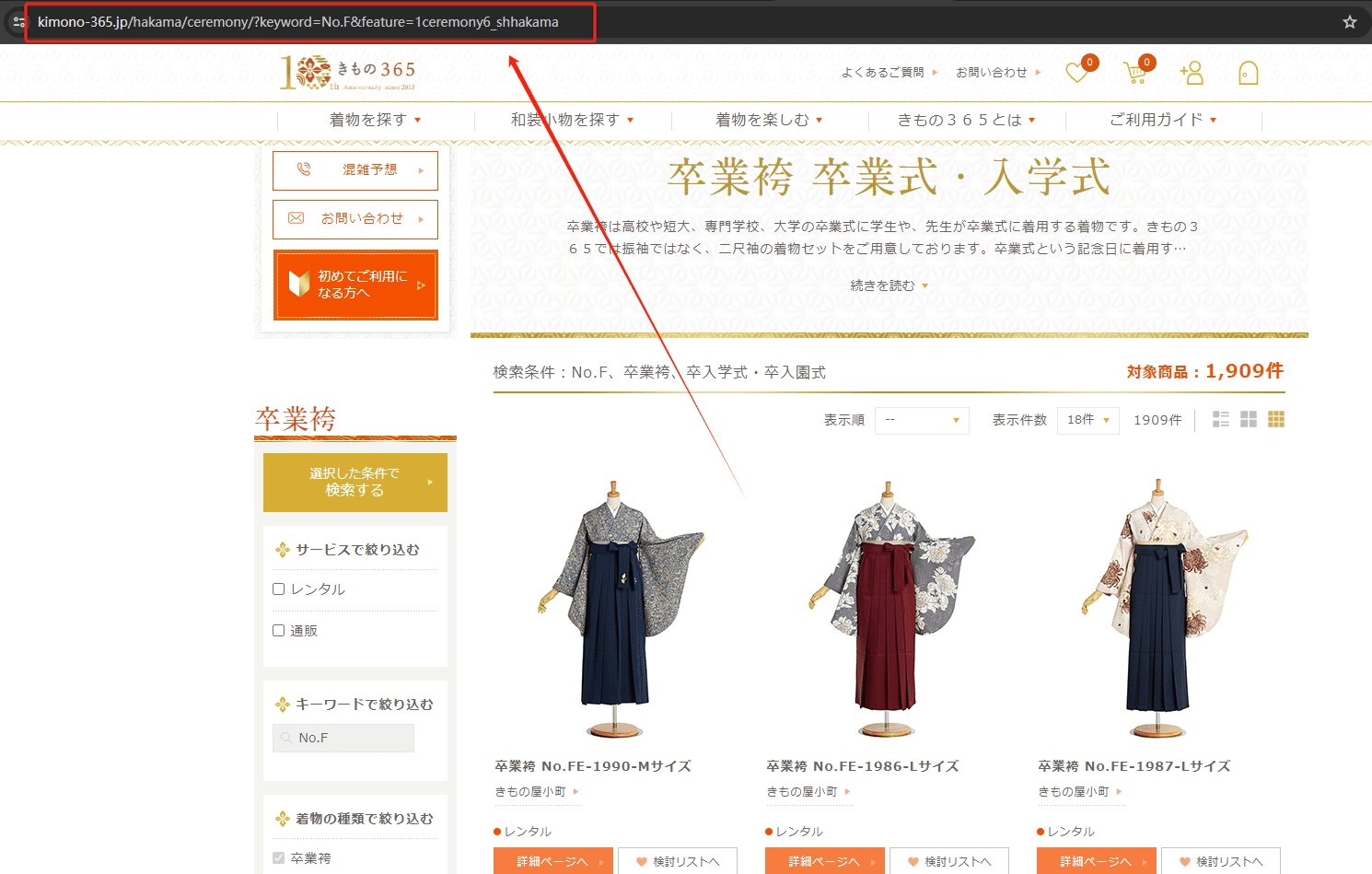
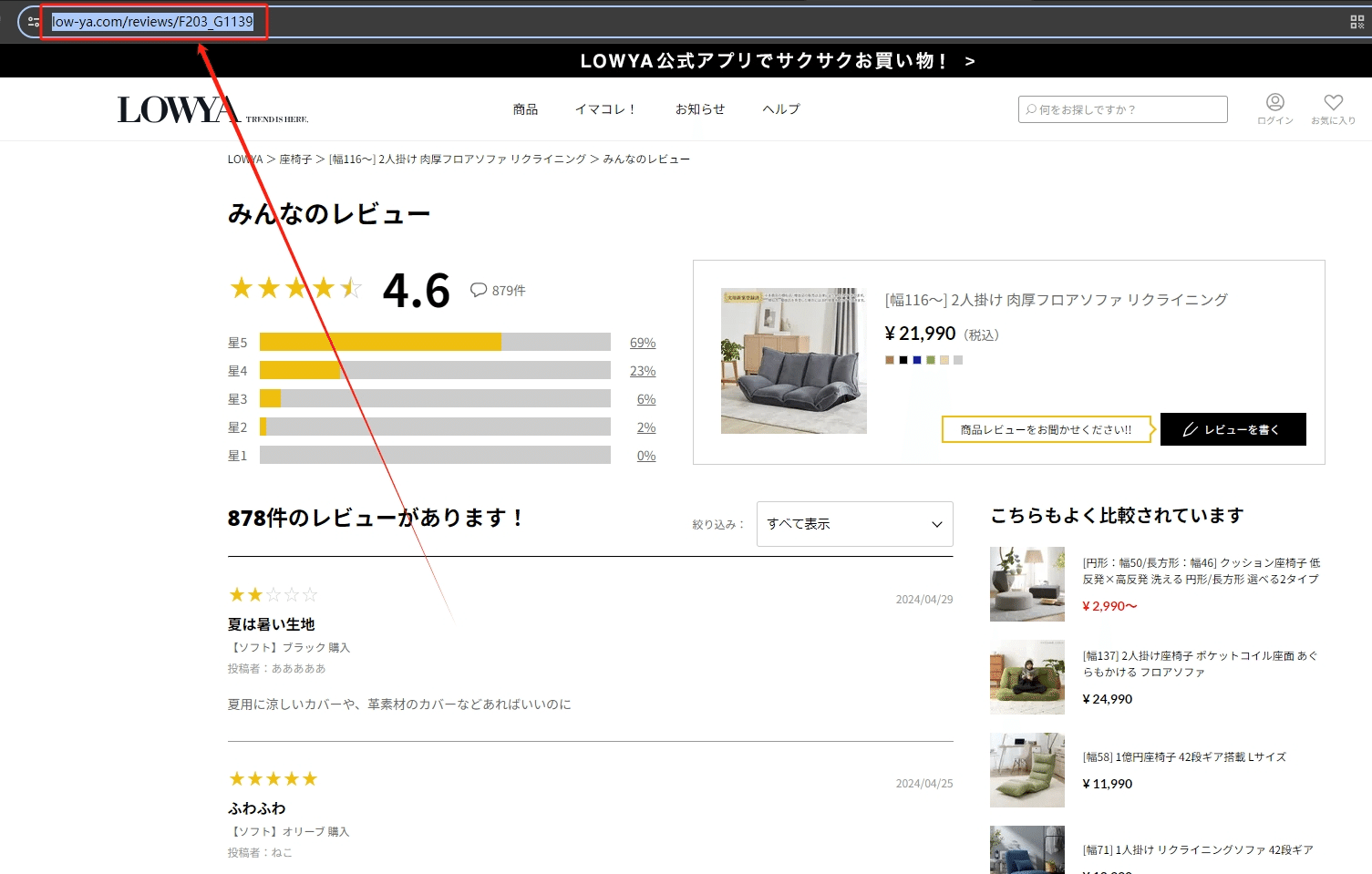
(1)URLをコピーする
今回はある人気商品のレビュー一覧ページのスクレイピング方法を紹介します。まず、URLをコピーしてください。
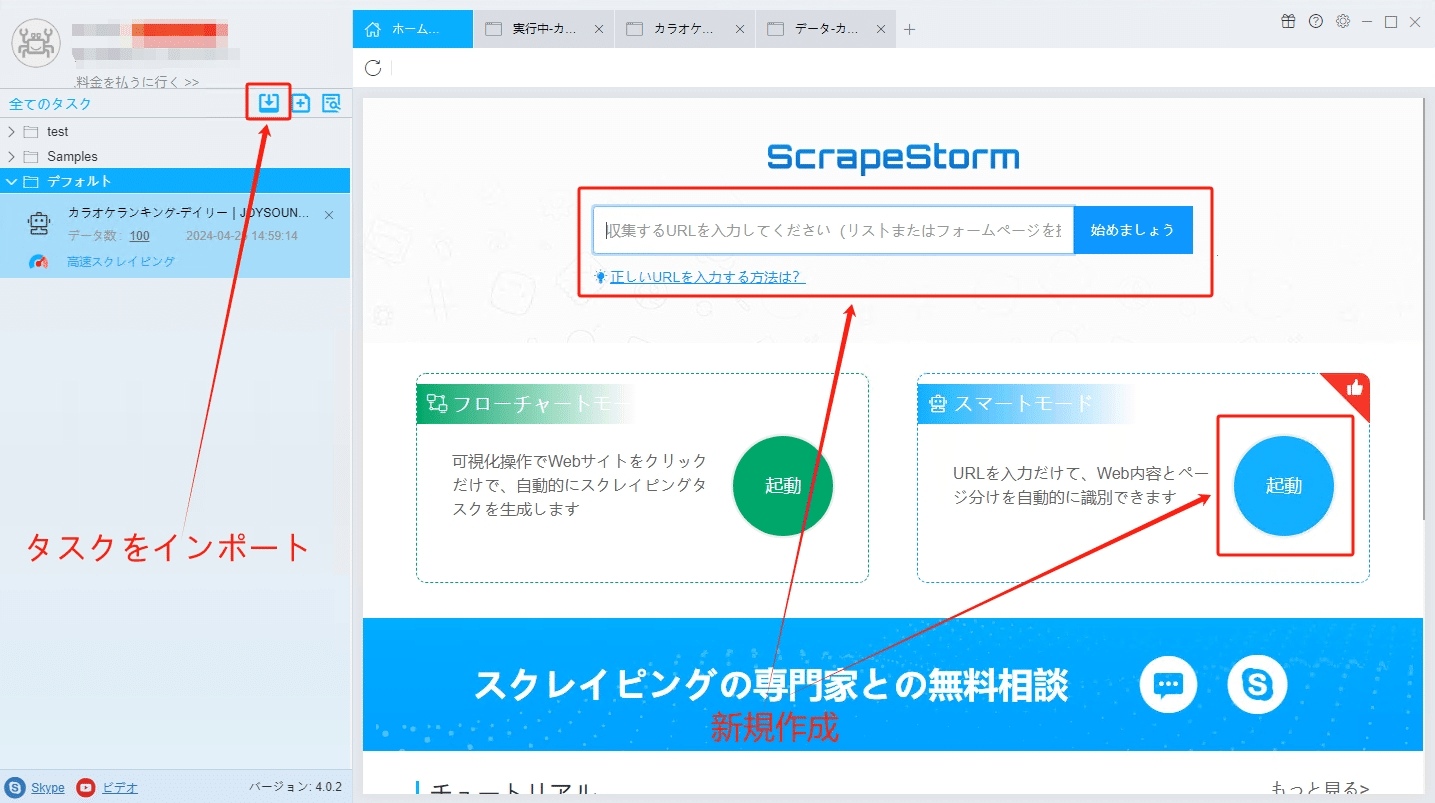
(2)スマートモードタスクを新規作成する
ScrapeStormのホムページ画面にスマートモードタスクを新規作成します。また、持っているタスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
スマートモードタスクの新規作成方法

2.タスクを構成する
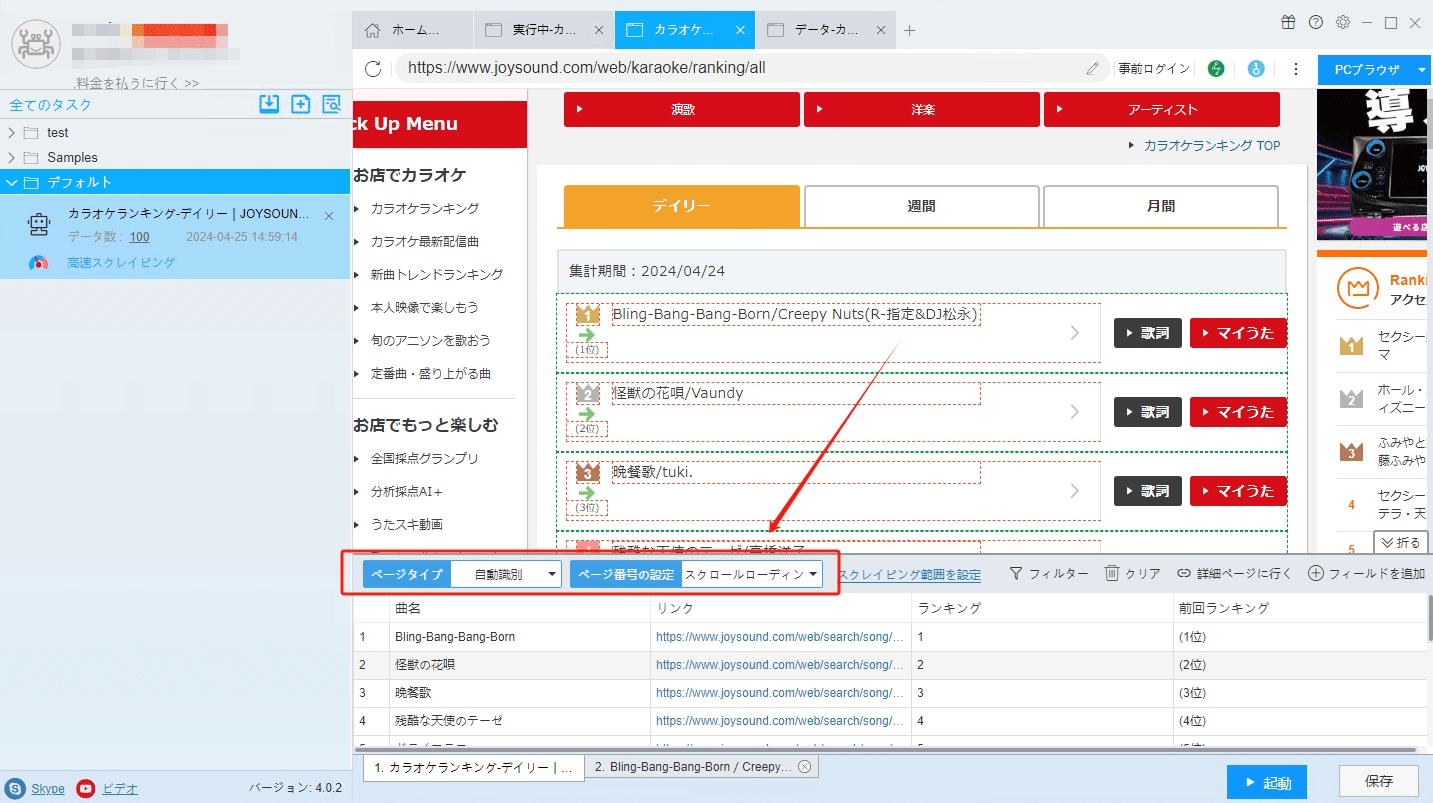
(1)自動識別
ScrapeStormは自動的にリスト要素とページボタンを識別できます。もし誤差があれば、手動で選択してください。下記のチュートリアルも参照してください。
ページ分けの設定方法

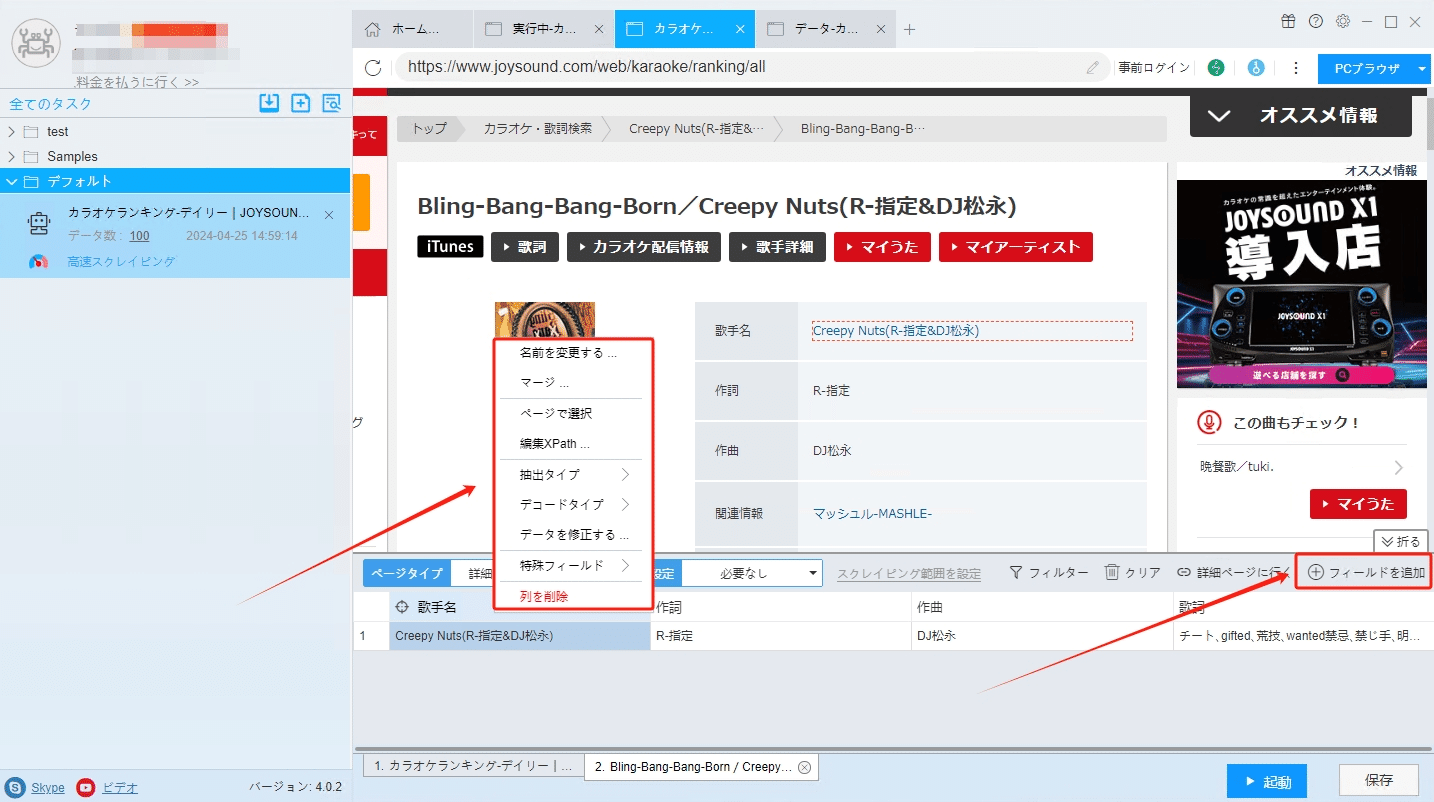
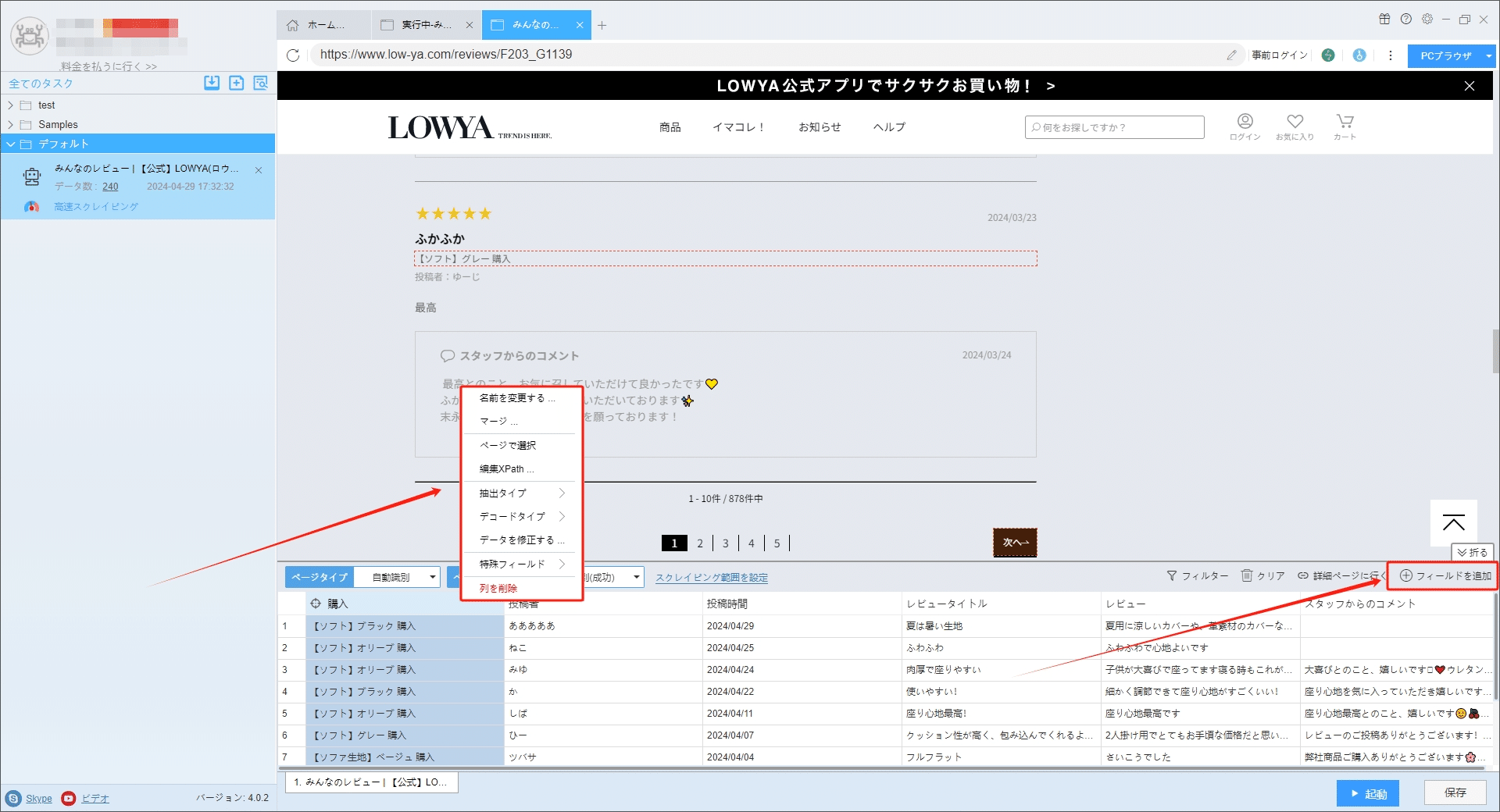
(2)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法
3.タスクの設定と起動
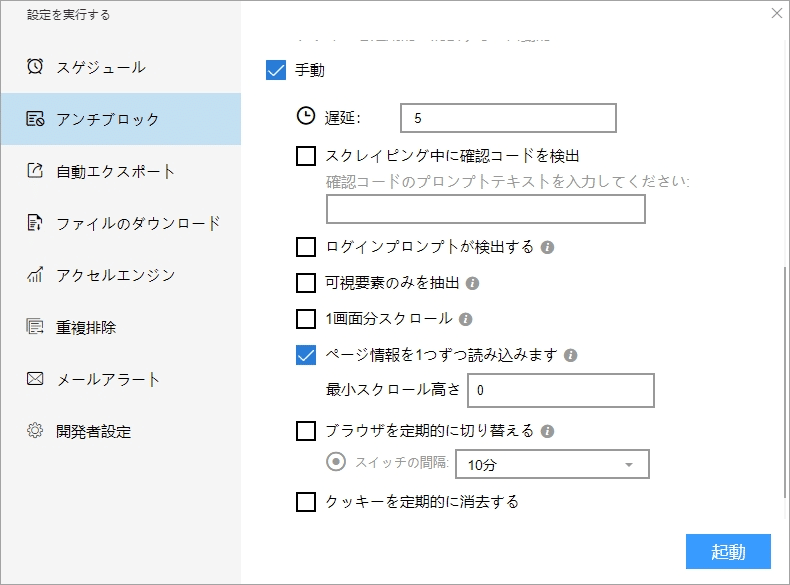
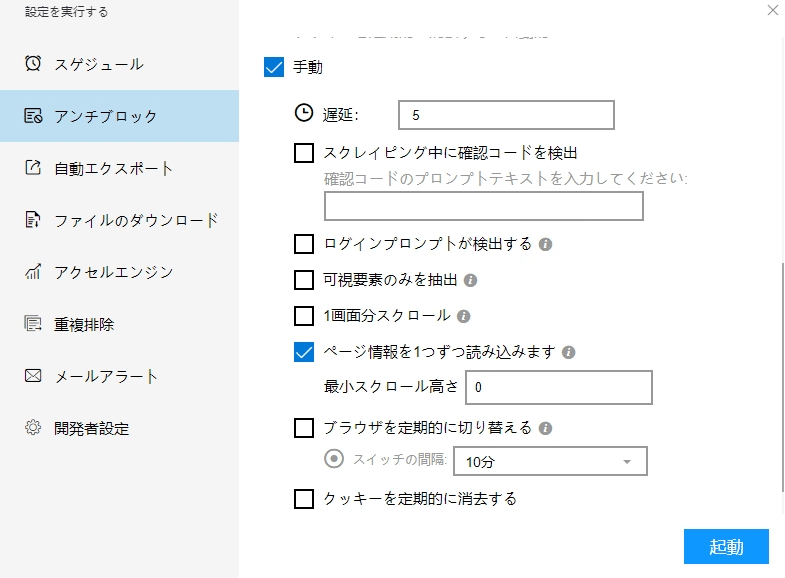
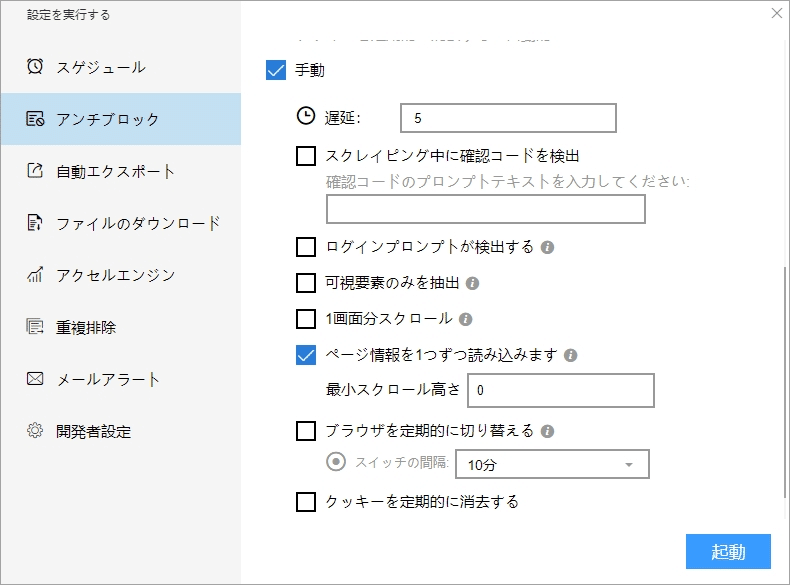
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。サーバーに負荷しないように、遅延時間を設定してください。5秒以上を推薦します。スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法
(2)しばらくすると、データがスクレイピングされる。

4.抽出されたデータのエクスポートと表示
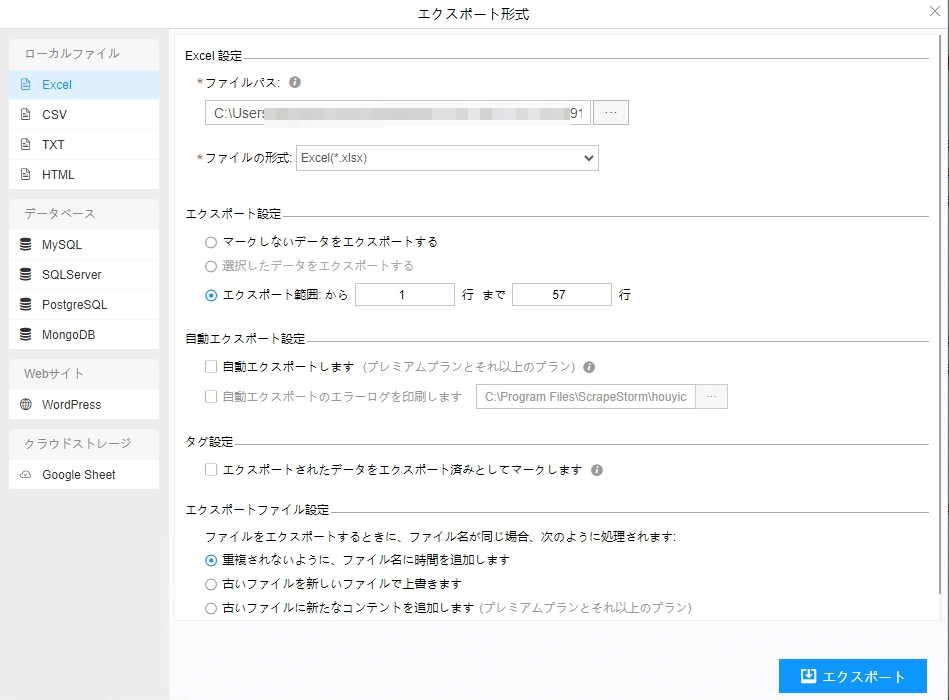
(1)エクスポートをクリックして、データをダウンロードする
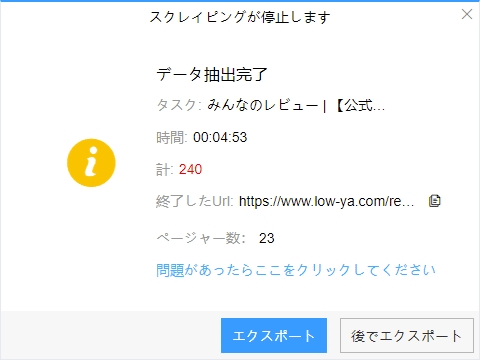
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法

Demoタスク:
インテリア・通販サイト!LOWYAから家具の情報をスクレイピングする.sst
https://drive.google.com/file/d/100r0S02N6NuANdc9BeV_y-poyYfM_x9A/view?usp=sharing
注意:法律違反しないため、抽出されたデータを悪用禁止です!